








En los sistemas de recirculación acuícola, la predicción exacta de la biomasa de camarones podría determinar la cantidad de alimentación adecuada y asegurar una calidad de agua estable, por lo que el desarrollo de una técnica de alimentación inteligente proporciona una guía importante para la cría de Litopenaeus vannamei.
En los últimos años, la aplicación del aprendizaje automático en la acuicultura ha incluido la predicción de indicadores de calidad del agua, detección temprana de enfermedades y brotes de marea roja, y la predicción de poblaciones de peces. La tendencia de la pesca inteligente se basa en el uso de tecnología de sensores para monitorear y regular los procesos de cultivo.
Bourke et al. (1993) desarrollaron un sistema de toma de decisiones que podría retroalimentar indicadores de calidad del agua en tiempo real. Wang et al. (2018) crearon un novedoso dispositivo sensor optoeléctrico para NO² -N en un sistema de recirculación acuícola (RAS, por sus siglas en inglés).
“La combinación de sensores con el Internet de las cosas y las tecnologías de inteligencia artificial se ha utilizado ampliamente en la acuicultura.”
En comparación con el modo tradicional de cría extensiva, el RAS es más favorable para las aplicaciones de sensores. Los RAS pueden proporcionar una alta producción debido a su entorno controlado y bioseguro basado en un ecosistema artificial.
El cultivo de camarones blancos (Litopenaeus vannamei) en RAS puede crecer a alta densidad, evitando virus dañinos. Mientras los mariscos están en un RAS, la biomasa de los organismos criados es difícil de calcular con precisión, especialmente cuando el tanque de cultivo es grande.
“Con la finalidad de garantizar una alimentación suficiente, una práctica común para medir la biomasa es el conteo y peso total mediante muestreo por unidad de área (Chen et al., 2019).”
La estimación precisa de la biomasa de camarones en un RAS proporciona una guía importante para su alimentación. Con la biomasa se puede determinar la cantidad de alimentación necesaria, asegurando la calidad del agua y adecuada nutrición para los camarones.
Se han llevado a cabo muchos estudios relacionados con la aplicación de modelos empíricos para predecir la biomasa del camarón. No obstante, los modelos no pueden aplicarse directamente a los RAS debido a los diferentes modos, métodos y entornos del proceso de cultivo.
Este artículo presenta el resumen de un estudio en el cual se utilizaron varios modelos para pronosticar la biomasa de camarones y así poder determinar la estrategia de alimentación más adecuada en un RAS.
Materiales y Métodos
Materiales experimentales y sistema
La cría de L. vannamei se llevó a cabo en dos empresas de China. Como se muestra en la Figura 1a y b, los experimentos se realizaron en el Tecnológico Ecológico de Yujia’ao (entre junio y noviembre de 2018) y en la Inversión de Guangdong Haimao (en el periodo comprendido entre junio y diciembre de 2019).

Durante el proceso de tratamiento del agua, se aplicaron rayos ultravioleta y ozono para prevenir virus y patógenos. Se instaló un dispositivo colector de desperdicios para garantizar la calidad del agua en cada tanque. A los camarones se le suministró alimento comercial seis veces al día.
“En la etapa inicial de cría, la cantidad de alimento fue de 5%–8% de la biomasa total de camarones, la cual disminuyó con el paso del tiempo de crianza y se redujo a ~3% de la biomasa total cultivada.”
La Figura 1d muestra un esquema del RAS. La combinación de la bomba centrifuga y el cono de oxigenación contribuyó al ciclo de recirculación. La bomba centrífuga extrajo agua a una gran altura dentro del biofiltro y, luego, la envió a través de una tubería y la recirculó por gravedad.
Se combinó un cono de oxigenación con una bomba de bajo flujo para proporcionar suficiente oxígeno disuelto.
Métodos de aprendizaje automático
Las redes neuronales artificiales (ANN, por sus siglas en inglés) se derivan de las redes neuronales biológicas del cerebro humano. A diferencia de las redes con solo unas pocas capas de lógica unidireccional, las ANN utilizan algoritmos para manipular la determinación y la organización de funciones.
“Las redes neuronales artificiales interconectadas suelen estar compuestas por neuronas que pueden manejar las entradas y seguir diversas situaciones.”
Se utilizaron varios métodos de ANN, incluyendo redes neuronales de regresión general (GRNN, por sus siglas en inglés), red neuronal de retropropagación (BPNN), máquina de aprendizaje extremo (ELM) y red neuronal recurrente (RNN) para desarrollar modelos de predicción de biomasa.
La función sigmoidea se aplicó en el proceso de desarrollo del modelo. GRNN, BPNN y ELM son redes neuronales de retroalimentación sin ciclos ni bucles.
Vector de soporte automático
El vector de soporte automático (SVM, por sus siglas en inglés) es una técnica eficiente de aprendizaje automático basada en teoría estadística.
Se enfoca en información limitada sobre muestras y se mueve entre la complejidad y la capacidad de aprendizaje de los modelos, los cuales poseen un conocimiento extraordinario de optimización a nivel mundial para mejorar la generalización.
Para la clasificación binaria lineal separable, la función principal del SVM es encontrar el hiperplano óptimo que divide todas las muestras con un margen máximo.
Optimización del modelo
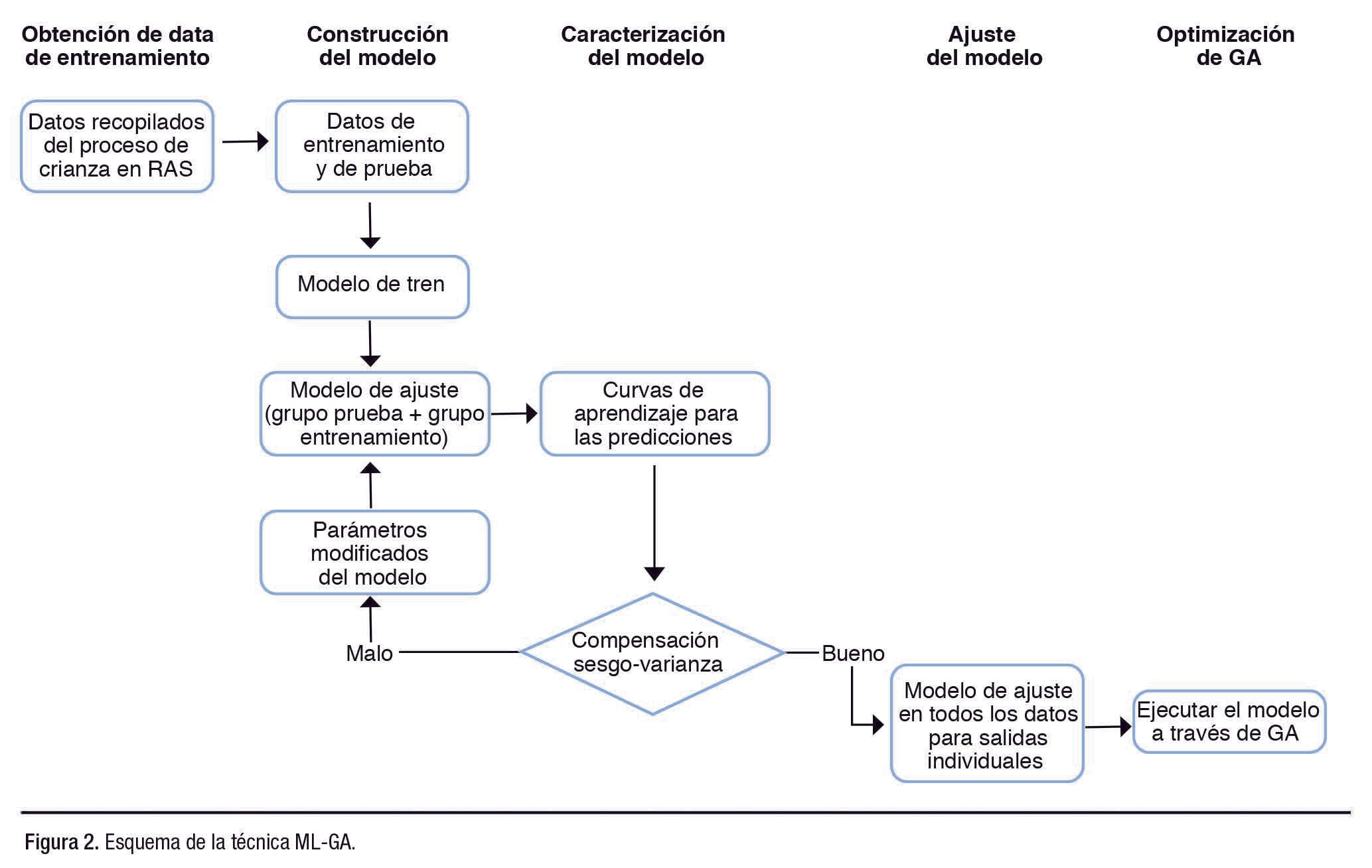
Se utilizó un algoritmo genético (GA, por sus siglas en inglés) para optimizar los métodos de aprendizaje automático, incluyendo ELM, BPNN y SVM. GA es un algoritmo evolutivo para optimizar un modelo computacional de manejo de datos con una combinación de selección, cruce y mutación para hacer evolucionar la población aleatoria inicial.
La Figura 2 muestra un esquema del aprendizaje automático de GA. El primer proceso de optimización de GA consiste en elegir una función de aptitud que mida el rendimiento de un conjunto de parámetros de entrada.
Diseño del sistema de alimentación inteligente
El entorno acuático debe regularse en función de la experiencia porque el RAS de camarones contiene un ecosistema artificial controlable. Diferentes niveles de experiencia conducirán a resultados de regulación variables y producción inestable.
La Figura 3 muestra el diseño del sistema de alimentación inteligente, en el cual existe una interacción compleja entre biomasa, cantidad de alimentación y calidad del agua.
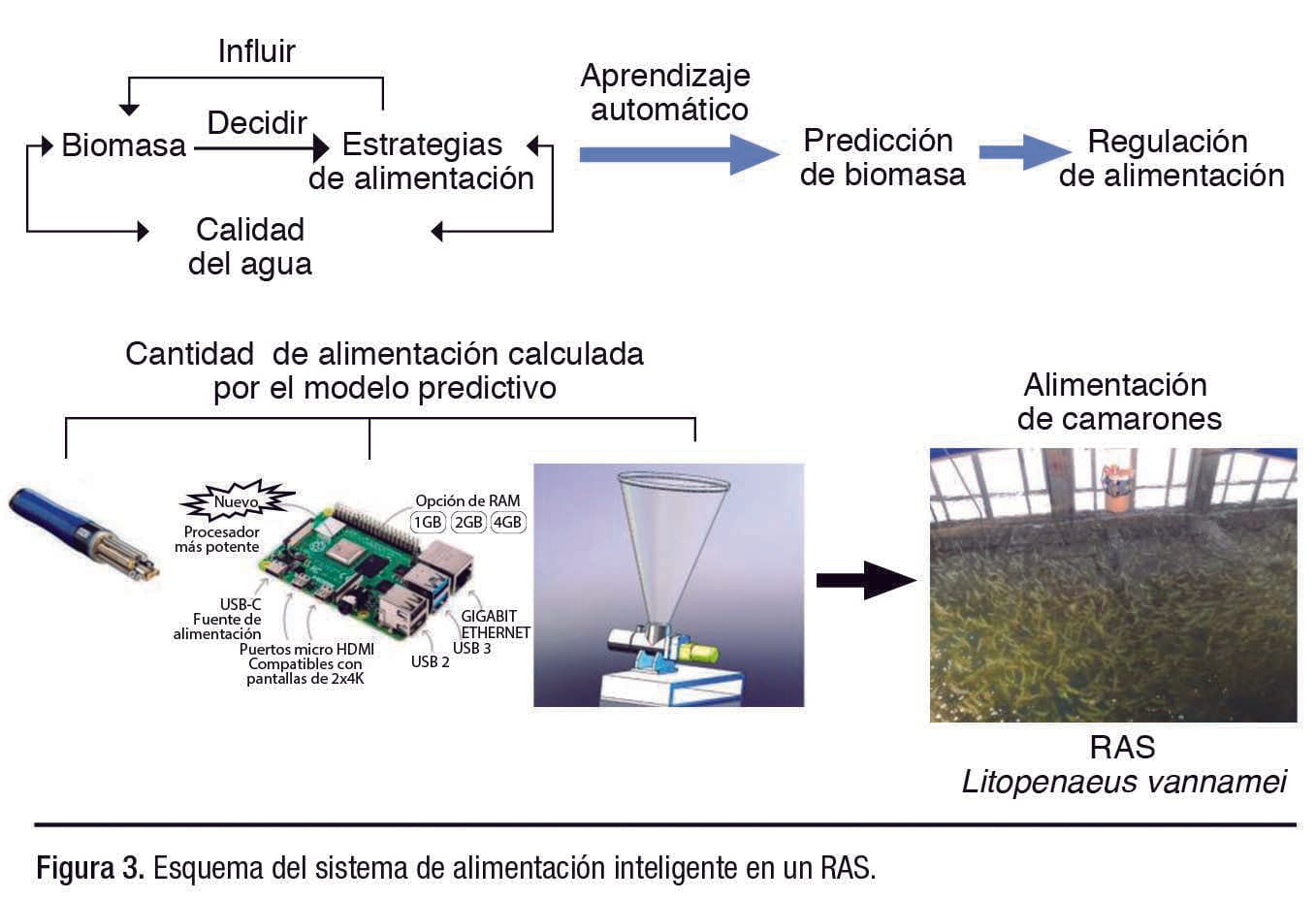
Se utilizaron enfoques de aprendizaje automático para calcular la cantidad de alimentación. Una vez integrado, el sistema puede leer el índice de calidad del agua medido por el sensor, llamar al modelo de aprendizaje automático y controlar la máquina de alimentación para regular la estrategia de alimentación en el RAS.
Resultados
Modelo de regresión lineal múltiple
En el modelo de regresión lineal múltiple (MLR, por sus siglas en inglés) se introdujeron exitosamente los parámetros: temperatura del agua, salinidad, pH, oxígeno disuelto, nitrógeno amoniacal total, NO² -N y cantidad total de alimentación. Cada variable necesitaba alcanzar la prueba-F antes de introducirse en el modelo.
“Cuando las variables introducidas ya no eran significativas para el modelo, las variables posteriores eran eliminadas para asegurar que la ecuación contenía solo variables explicativas significativas. Las variables se introdujeron paso a paso mediante arreglo y combinación para asegurar que la ecuación obtenida tuviera el mejor poder explicativo.”
Finalmente, se generó una expresión con cuatro variables explicativas como sigue:
![]()
donde W representa la biomasa del camarón (kg/m³), x¹ la temperatura del agua (°C), x² la salinidad (‰), x³ el pH y x4 la cantidad total de alimento (kg/d).
El modelo MLR pasó la prueba t-(p<0.05) y F-(F = 148.512) con un coeficiente de regresión (R²) de 0.882.
Modelos de entrenamiento de aprendizaje automático
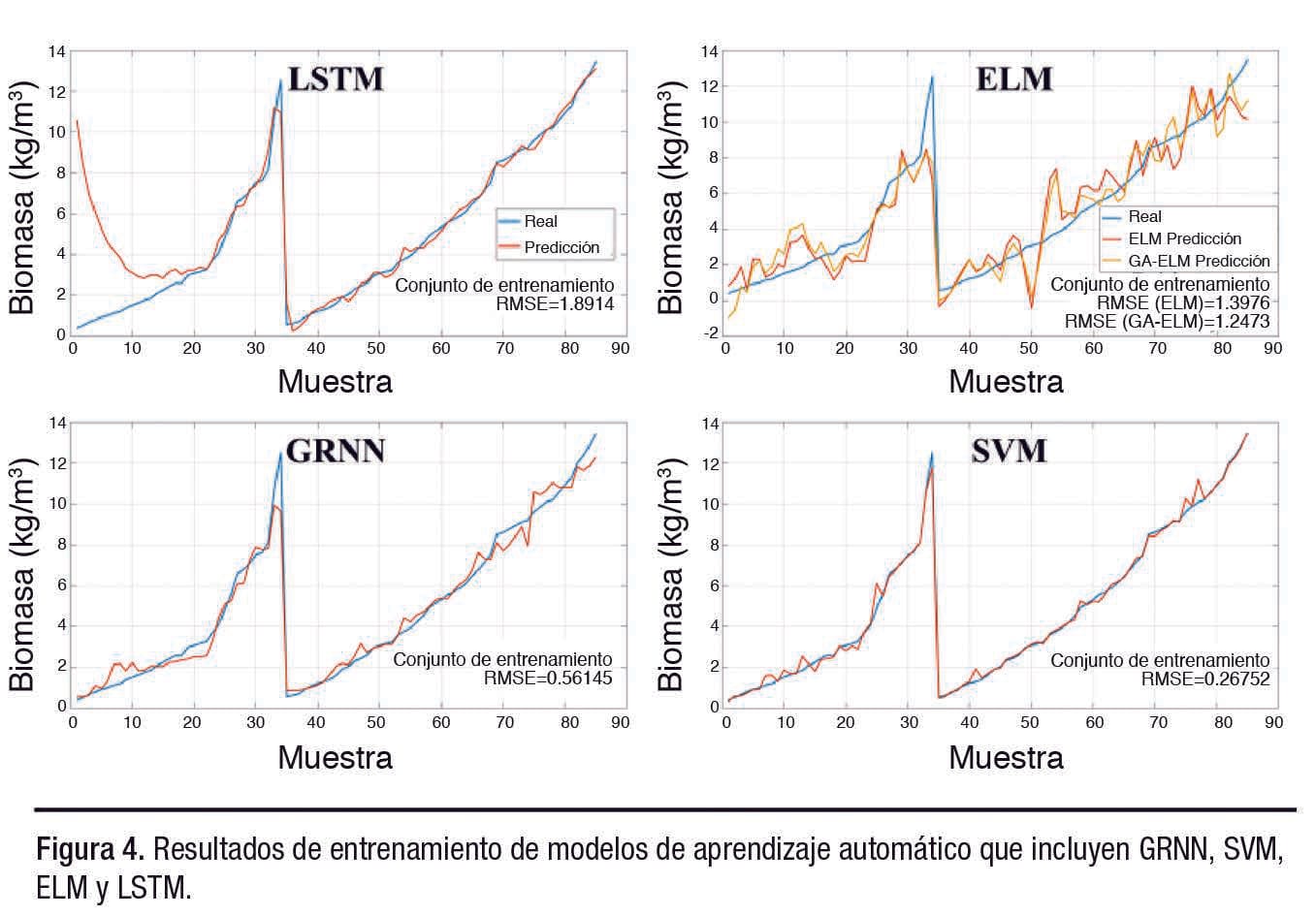
Los métodos de aprendizaje automático, incluidos GRNN, BPNN, LSTM, ELM y SVM, se utilizaron para desarrollar modelos.El conjunto de datos se dividió en 75% entrenamiento y 25% prueba. Los datos del conjunto de entrenamiento se emplearon para desarrollar los modelos predictivos, y los datos del conjunto de prueba se sustituyeron en los modelos para evaluación y verificación.
La Figura 4 ilustra las curvas de distribución de datos de los conjuntos de entrenamiento GRNN, SVM, ELM y LSTM. El error cuadrático medio (RMSE, por sus siglas en inglés) mostró que los resultados de cálculo arrojados por el modelo GRNN y SVM eran precisos y que la capacidad de precisión del conjunto de entrenamiento era estable.
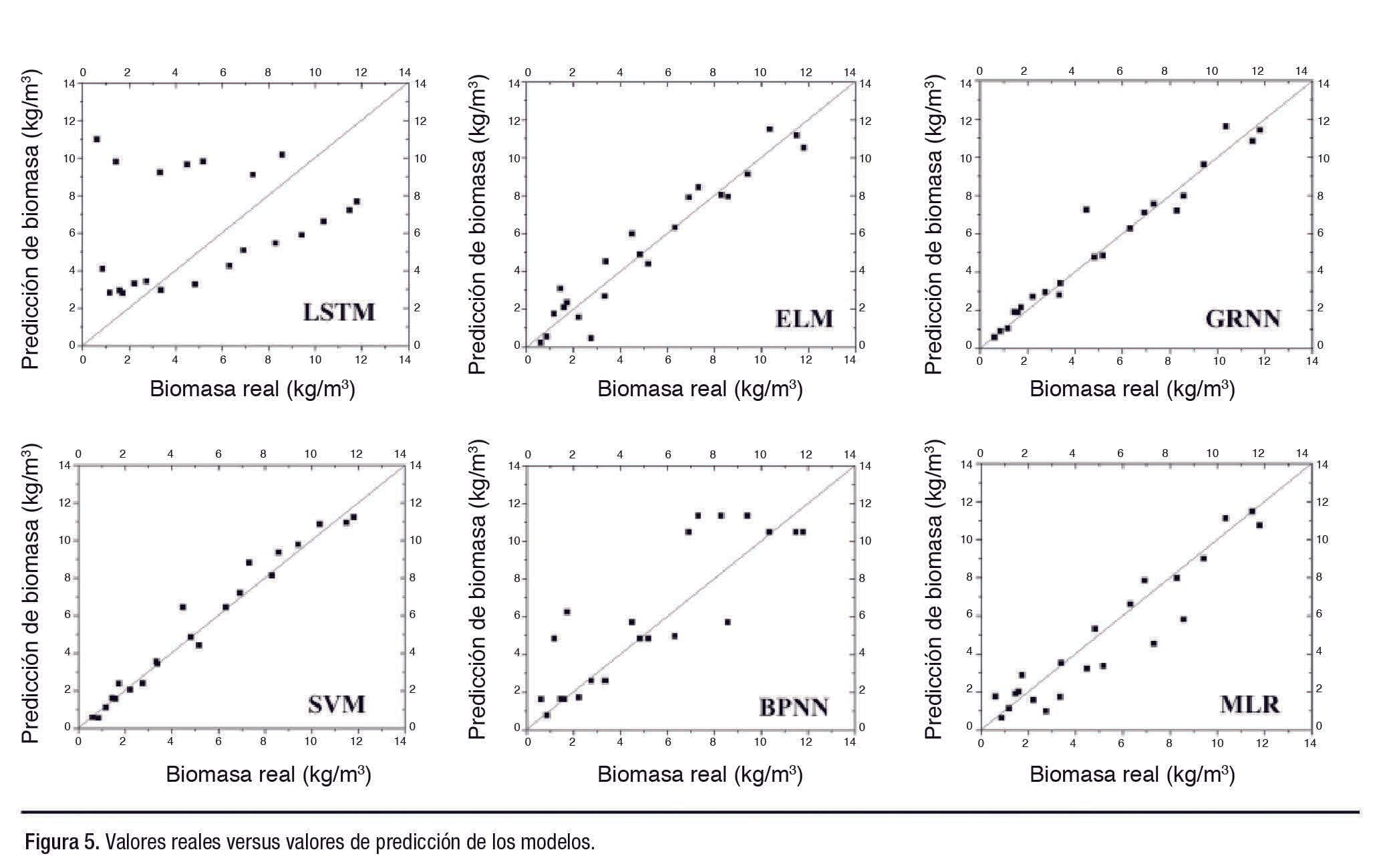
Predicción de rendimiento
El conjunto de prueba contenía 22 puntos de datos grupales. El rendimiento de la predicción se evaluó por observación preliminar del grado de solapamiento entre el resultado previsto y el valor real. La Figura 5 muestra los valores reales comparados con los previstos para el conjunto de prueba.
Comparación de los modelos
Los diseños residuales pueden utilizarse para estimar si los errores de predicción son consistentes con los errores estocásticos. La Figura 6 muestra los diseños residuales de los modelos de predicción de biomasa de camarones. Los residuos representan la diferencia entre el valor real y el valor previsto de la biomasa de camarones.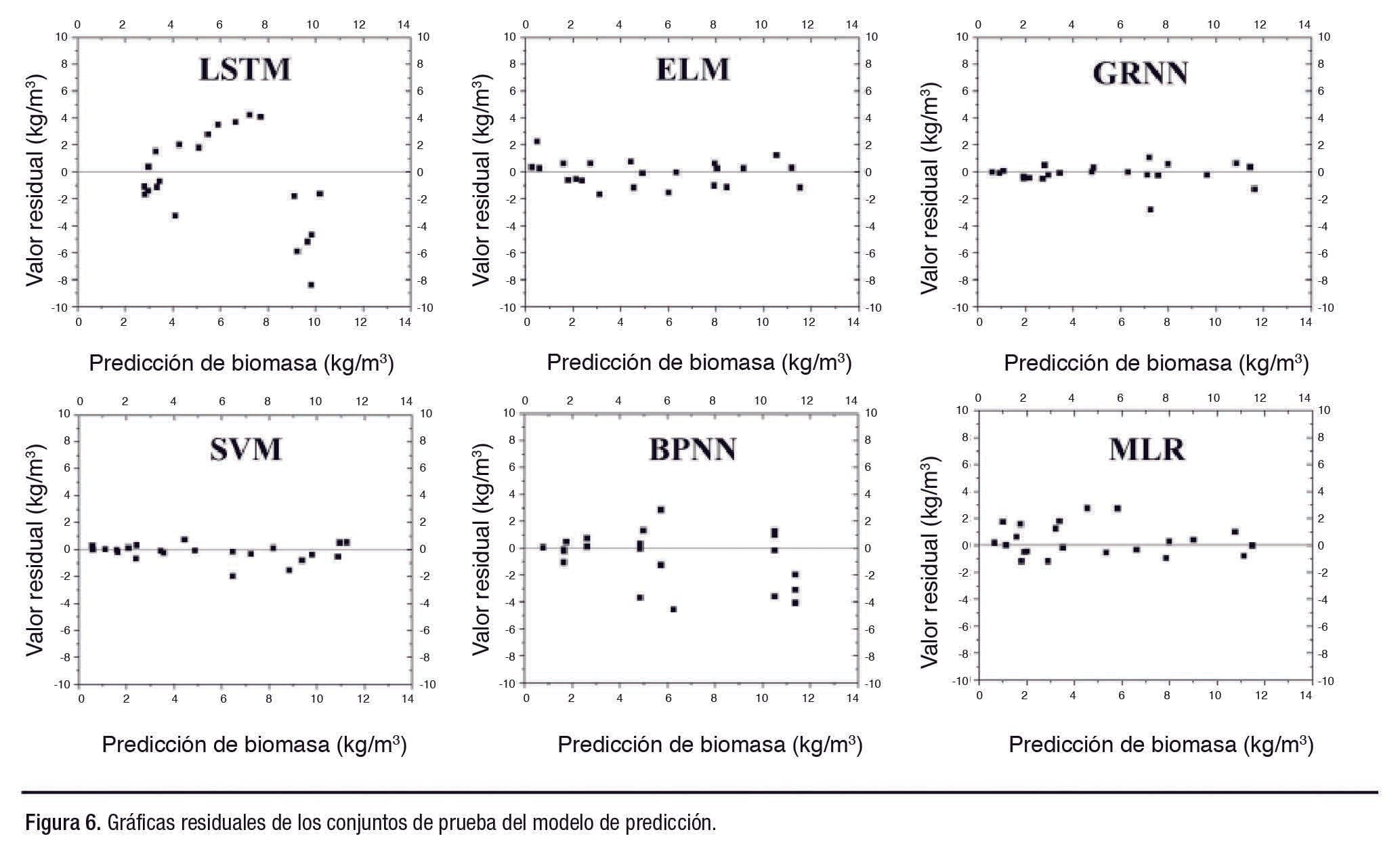
Conclusión
Se utilizaron los métodos MLR, ANN y SVM para construir modelos de predicción de biomasa para L. vannamei en RAS.
El método MLR aportó cuatro variables explicativas principales: temperatura del agua, oxígeno disuelto, pH y cantidad total de alimento, permitiendo obtener una relación lineal entre la biomasa de camarones y sus principales variables explicativas, pasando la prueba t y la prueba F (R² = 0.882).
Se desarrollaron modelos de predicción de biomasa basados en enfoques de aprendizaje automático con el conjunto de datos, y se empleó un algoritmo genético para optimizar los modelos. Después de comparar los resultados previstos, el análisis residual y los índices de evaluación entre diferentes modelos (RMSE = 0.6500, MAE = 0.4368, MAPE = 3.70 %, precisión = 90.91 %), se selección SVM como el método óptimo de predicción de la biomasa de camarones.
En síntesis, se desarrolló un modelo de predicción de biomasa de camarones de respuesta rápida para un RAS utilizando el método SVM con optimización GA. El sistema de alimentación inteligente puede aplicar el modelo SVM para regular la cantidad de alimentación precisa en un RAS de L. vannamei.
Esta es una versión resumida desarrollada por el equipo editorial de Panorama Acuícola Magazine del artículo titulado “INTELLIGENT FEEDING TECHNIQUE BASED ON PREDICTING SHRIMP GROWTH IN RECIRCULATING AQUACULTURE SYSTEM” escrito por FUDI CHEN y MING SUN – Chinese Academy of Sciences, Qingdao National Laboratory for Marine Science and Technology, Dalian Key Laboratory of Conservation of Fishery Resources, China, YISHUAI DU, JIANPING XU, LI ZHOU, TIANLONG QIU y JIANMING SUN – Chinese Academy of Sciences, Qingdao National Laboratory for Marine Science and Technology, China.
La versión original, incluyendo tablas y figuras, fue publicada en MAYO, 2022 en AQUACULTURE RESEARCH.
Se puede acceder a la versión completa a través de https://doi.org/10.1111/are.15938




